
Phenom II X4 955 Black Edition
Intel's Nehalem has raised the stakes, combining a superior architecture with what some might call some very dirty tricks like dynamic overclocking or Turbo Boost of single cores but in all fairness, whatever works works and adding custom adaptational rmechanisms to accomodate the heterotypic landscape of applications in transition from single- to multithreading is a perfect example of thinking outside the box with surprisingly good results. On the other hand, if it is out there in the public domain, then the technology is fair game for anyone - with the minor issue of intellectual property that could throw a monkey wrench into the global adoption. Needless to say that there is a lot of prior art in the public domain, resulting in the fact that patent protection often can only be obtained for some very specific ways of doing things - rather than the operational principle - even if the specific way is the most elegant way of doing things. Consequenty, sometimes, we see some more awkward realizations of technology maturing to life, or maybe, they only look awkward at first glance, because we have gotten used to an alternative method of doing things first. Those are some of the thoughts I have been pondering in the last two weeks, benchmarking and evaluating AMD's latest desktop processor a.k.a. Phenom II X4 955 Black Edition.
Phenom II X4 955 Black Edition
The New Stuff
With respect to hardware, nothing really seems to have changed, there are no changes in chache size, the '955 features the full size 6 MB L3 cache, nor has the transistor count changed. Rated frequency is up a bit, from 3.0 GHz in the X4 940 to 3.2 GHz in the 955 and, of course, the socket pinout is AM3, meaning a 938 pin-count and native DDR3 support with backward compatibility with any AM2/AM2+ board as long as the BIOS supports the new CPU. At the same time, AMD is launching the Phenom II X4 945, which essentially replaces the X4 940 in Socket AM3 flavor and runs natively at 3.0 GHz. In so far, there is really nothing new but soime tweaks must have been applied because new BIOS revisions are required to operate the new CPU offerings. Moreover, we observed a few anomalies in benchmarking behavior that further supports our suspicions that more fine-tuning went on under the hood then AMD publicly discloses.

Phenom II X4 945
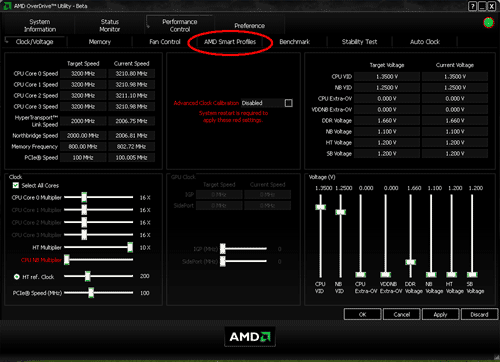
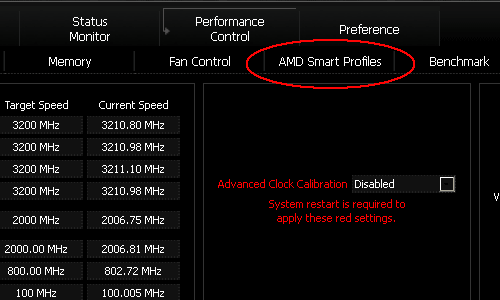
Before going into benchmarks - arguably what a lot of this article is all about, there are a few improvements in AMD's Overdrive (AOD) version 3, a beta version of which we had, introducing an amalgamate of EPP and XMP and Turbo Boost in a single software interface. And guess what, it is actually done in a pretty smart fashion (no surprise there since I had my fingers in some of the feature definitions).
{mospagebreak_scroll title=Black Edition AOD Profiles}
Dynamic Overclocking / Smart Profiles
One major source of grief over the past few months has been Intels Turbo Boost technology - at least for some people who thought it a devious, deceitful spin to fake performance that only existed under extremely tight controlled lab conditions. Even if we were to subscribe to this point of view, Turbo Boost is an elegant way of bridging the transition between software poorly optimized for symmetric multiprocessing (including Microsoft Operating Systems) and truly multithreaded software or even virtual machines. In the first scenario raw clock frequency rules, in the second situation thermal and power situations are setting the limitations for the operating envelope.
Consequently, having a flexible solution that scales with the number of busy cores - or rather inversely with the number of threads - is the best of two worlds. Intel implements this solution on the BIOS level - after all, each core domain has its own clock anyway. AMD processors had their individual clock domains quite a bit longer than Intel but for whatever reasons never implemented this kind of solution - until now that is. In contrast to Intel, however, AMD is going a different route, and are using their AMD Overdrive Utility to selectively bind certain profiles to certain applications, in which the "loaded" cores are cranked up 400 MHz beyond the nominal top frequency and the "idle" cores are clocked down to 400 MHz below the nominal rated frequency. Bear in mind that the Smart Profiles only applies to Black Edition CPUs, if the muliplier is locked internally, then AOD will not be able to raise it in software either. Profiles can be downloaded from a dedicated AMD server by simply clicking an "update" button in the AOD GUI. These profiles will become public domain sometime in the next week or whenever AMD's legal department signs off on the nitty gritty.
Phenom II X4 945
Phenom II X4 945
Some of the "Smart Profiles" details are still a bit sketchy, particularly with respect to the necessity of down-clocking the idle cores which could be done in a more efficient manner by simply using P-states or C'nQ. However, as we and others found in the past, the wake-up and ramping delays in the case of C'nQ, to bring an idle core up to speed can have some rather harsh effects on the outcome of benchmarks, which can be avoided by using the Smart Profiles-based clocking scheme.
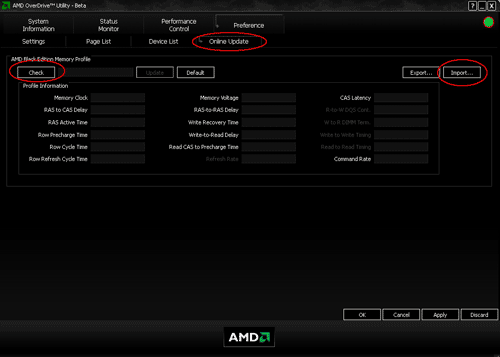
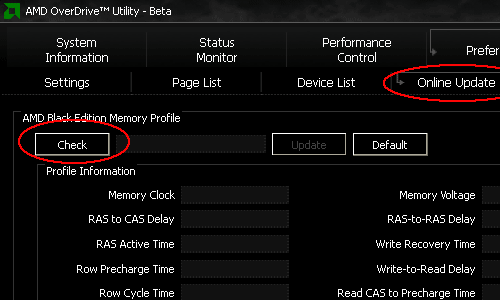
Black Edition Memory Profiles
An additional novelty is introduced under the acronym BEMP, short for Black Edition Memory Profile. The way BEMP works is that AOD will read the hex string of the memory part number from the SPD and cross-check with a dedicated server hosted by AMD for any profiles corresponding to the particular part number. If there is a match, the system will download the profile in XML format which is then read by AOD and allows updating of the memory settings "in software" which, in most cases, will require a reboot upon which the new frequency and timing parameters are loaded.
Sounds familiar? In essence, it is the same thing as what nVidia has been pushing with their EPP and Intel with their XMP profiles. Personally, I actually prefer AMD's solution, if for nothing else but the simplicity of the approach and the fact that no special programming of the memory modules is required. In fact with a little bit of hacking, BEMP is appliccable to any memory module, since AOD also allows simple "importing" of profiles that can be edited in notepad according to any user's wishes.
Phenom II X4 945
Phenom II X4 945
The profiles corresponding to any specific part numbers can be downloaded as XML feed from AMD's server
Phenom II X4 945
AOD also allows to import profiles in XML format from the hard disk.
{mospagebreak_scroll title=CPU Specs and Test Configuration} AMD Phenom II X4 955 BE and X4 945 Processor Specifications

Most of the benchmarking was done on both AM2+ and AM3 platform, in case of the latter, we used ASUS' M4A79T Deluxe with the 0037 beta BIOS.
| Processor Frequency: | X4 955: 3.2GHz / X4 945: 3.0GHz |
| Core Multiplier: | X4 955: Unlocked / X4 945: 15 x |
| L1 Cache Sizes: | 64K of L1 instruction and 64K of L1 data cache per core (512KB total L1 per processor) |
| L2 Cache Sizes: | 512KB of L2 data cache per core (2MB total L2 per processor) |
| L3 Cache Size: | 6MB (shared) |
| Memory Controller Type: | Integrated 128-bit wide memory controller * |
| Memory Controller Speed: | Up to 2.0GHz with Dual Dynamic Power Management |
| Types of Memory Supported: | Support for unregistered DIMMs up to PC2 8500 (DDR2-1066MHz)/ PC3 12800 (DDR3-1600**) |
| Theoretical Memory Bandwidth: | Up to 25.6GB/s |
| HyperTransport 3.0 Link: | One 16-bit/16-bit link @ up to 4.0GHz full duplex (2.0GHz x2) |
| HyperTransport 3.0 Bandwidth: | Up to 14.4GB/s |
| Total Processor Bandwidth: | Up to 36GB/s total bandwidth |
| Packaging: | Socket AM3 938-pin organic micro pin grid array (micro-PGA) |
| Fab location: | Fab 36 wafer fabrication facilities in Dresden, Germany |
| Process Technology: | 45-nanometer DSL SOI (silicon-on-insulator) technology |
| Approximate Transistor count: | ~ 758 million (45nm) |
| Approximate Die Size: | 258 mm2 (45nm) |
| Max Ambient Case Temp: | 71° Celsius |
| Nominal Voltage: | 0.875 - 1.425 Volts |
| Max TDP: | 125 Watt |
*NOTE: MC configurable for dual 64-bit channels for simultaneous read/writes
**NOTE: Above DDR3 10666 (1333 MHz) only one DIMM per channel is supported.

The biggest difference between the AM2+ and the AM3 platform is the support for DDR3. Interestingly since the controller supports both DDR2 and DDR3, the voltage tolerance on the controller is up to 2.3V irrespective of the generation of DDR memory used.
Test Configuration and Power Measurements
We tested the AM3 Phenom II X4 955 BE in the following system configuration:
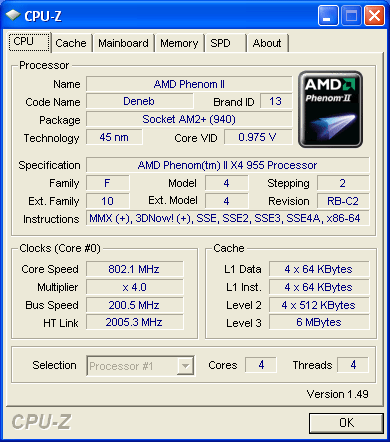

Note that CPUZ still identifies the processor package as AM2+ (940 pin). If CnQ is enabled, both processors are throttling down to a 4 x multiplier and are running the idle cores at 800 MHz and reduced voltage (1.025V) for maximum power efficiency. Also note that the NB/IMC is running at 2.0 GHz on both CPUs.
Having learned our lessons regarding power measurements on the Nehalem platform, we verified that the 4+1 phases of the VRM receive their power from the 12V auxiliary power plug by ohming out the connections between the MOSFETs and the plug on one side and the MOSFETs and CPU socket on the other side. In theory, showing the electrical continuity does not exclude additional supply power coming in from the 24 pin main eATX connector, however, we also checked there and got "open circuit" readings. This means that we can with reasonable certainty claim that the entire CPU power, including cores and NB/IMC (but excluding I/O power) is derived exclusively from the auxiliary 4-pin 12V input. Details are given on this page.
Benchmark Overview
* We used a fresh install of XP-32 Pro and upgraded to Vista 32 Home Basic Edition and then went back to XP since Vista is plain and simply unacceptable as Operating System.
Power Measurements
Looking at system power consumption is interesting to a certain degree, however, for all practical purposes we are more interested in the isolated CPU power consumption. To estimate the latter, we used the same power measurement setup as in previous reports. Briefly, we used a Fluke 80i-410 AC/DC current probe in combination with a Wavetek Meterman 30XR multimeter to measure current through the isolated +12V supply lines feeding into the CPU VRM. To increase granularity of the measurements, we ran the supply lines in a triple loop through the clamp. The clamp itself was calibrated using a BK Precision model 1692, 30V 40 A DC power supply. Since there is a temperature dependency of the probe, we monitored the zero-current offset at the beginning of each measurement as well as at the end of each run. If the values drifted we retook the measurements. Despite these precautions there are possible deviations of the read-out from the real current, however, these errors mostly affect the lower (processor idle) measurements. We estimate that the errors should not be more than 10% at the lower end of the data and less than 5% in the mid and higher data range. Moreover, since the same procedures were applied to all processors tested, there may be an offset in the absolute numbers, however, the relation of the individual cores to each other with respect to power consumption should be fairly accurate.
In addition to the method outlined above, we used a modified PSU to run the 12V line directly through the Wavetek Meterman and read out the current. Both methods gave identical results.
{mospagebreak_scroll title=Memory Subsystem}
Memory Subsystem Performance
The new processors have ramped up the NorthBridge/DC frequency to the nominally specked frequency of 2.0 GHz, a 200 MHz or 10% increase in clock speed from the X4 920 and 940 releases. Bear in mind though, that the former had an artificially reduced NB/DC clock frequency in order supply enough yield to the market and avoid yet another paper launch, which would have been the last thing AMD could afford in the current dire straits. With higher switching frequencies of the memory controller, we should expect improvement in memory performance, not as much in memory bandwidth but certainly in the latency sector.
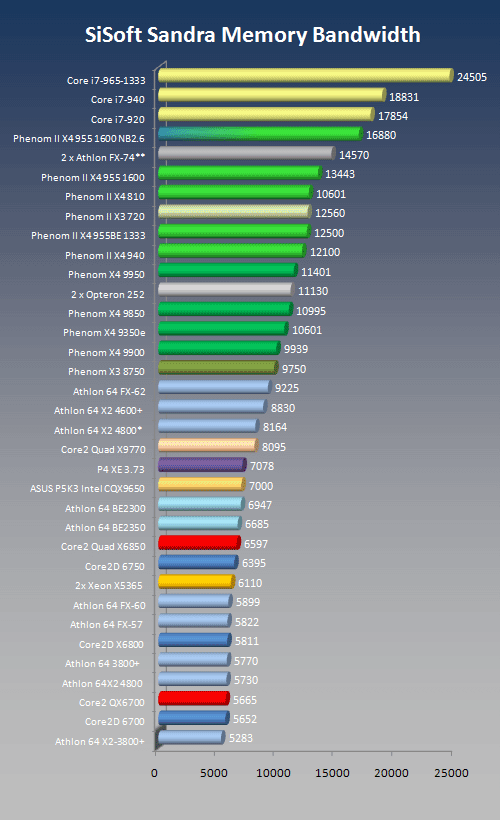
Even with DDR2, the new processors provide a slightly better performance in Sandra's memory bandwidth benchmark. The actual differences between the X3 720 and the X4 810 are not relevant.
With the imminent demise of the Core2 architecture, raw memory bandwidth is rapidly losing its importance as limiting factor for system performance since both the Core i7 and any of the AMD platforms have more than enough bandwidth available to saturate the cores in even the most data-hungry applications. At the same time, latencies are moving up again towards a spotlight position. In this context, it is also important to look at the differences between the AMD and Intel Core i7 implementations, where the first features two independent DRAM Controllers (DC0; DC1) that are connected via crossbar to each core and can be configured to un-ganged mode, meaning that one controller can read while the other one is writing (updating data) to the memory array. Intel on the other hand still appears to embrace the tour-de-force approach, where all controller sub-units serve their own respective channel but abide by one master control set. In other words, address and commands are triplicated by each of the three DC subunits but essentially they are all synchronized to perform the same way and just increase the data path by 3 x to a 192-bit width. The inherent granularity issues aside (which don't seem to bother the Core i7 architecture too much anyway), let's go back to the Deneb architecture to see how a 10% increase in DC frequency and L3 clock impacts the overall memory latencies as measured by Cachemem 2.65.
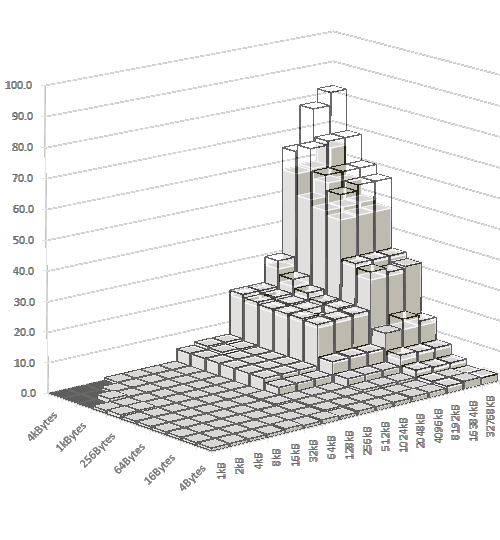
Everything else being equal, we overclocked the X3 720 to 3.0 GHz for an apples to apples comparison between the X4 940 and the X3 720 in terms of memory and cache access latencies. The X4 720 is shown as solid columns, the X4 940 is represented by the transparent columns. Lower is better!
Across the bench (L3 and system memory), the improvement in latency is roughly 10% which is better than what we would have expected. It is important to bear in mind that Cachemem, like any other benchmark, uses a regular stride pattern across the physical address space rather than generating "random" addresses in the physical memory address space. Random addresses would generate worst case scenarios and even though locality-based clustering of data is part of any memory management strategy, worst case IS the most important parameter when it comes to smoothness or lack thereof as for example in "minimum frame rates". On the other hand, randomness is difficult to quantify and prone to benchmark optimizations without any significance for real world performance. With that in mind, Cachemem is perfectly fine as benchmark as long as we are aware of the limitations. {mospagebreak_scroll title=Power Consumption, Windows Idle}
Windows Power Consumption (Idle), CnQ Enabled
Idle power is nominally small but since most systems spend the most of their uptime in idle mode, it does constitute a considerable power factor. Moreover, from a CPU standpoint, low power in idle states is an important part of thermal, and by extension, acoustic management of the PC. With one of the contenders running on three cores only, how much power savings can be achieved - if any? At the same time, given the fact that the NB/IMC including the L3 cache is running faster on today's candidates than on the previously examined Phenom II X4 940, we might even see an increase in idle power since the NB/IMC portion constitutes a major contributor to the idle power picture.
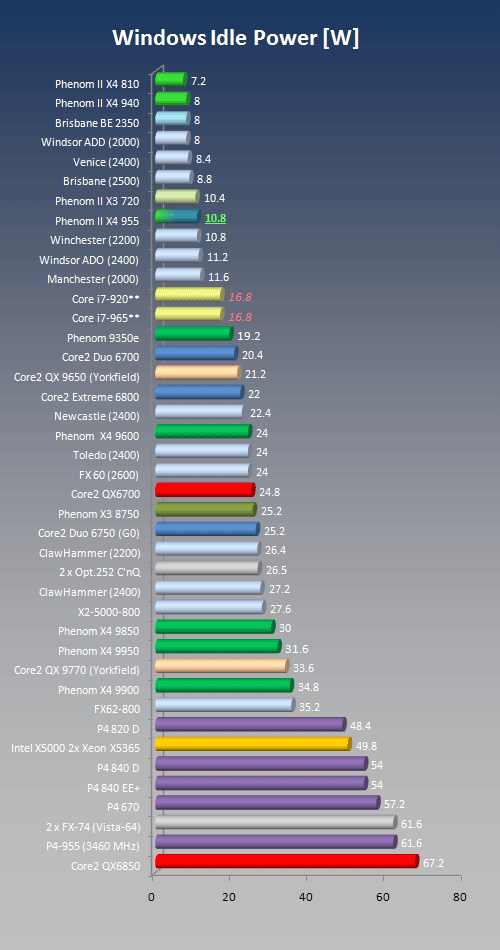
Power consumption in [W], lower is better. The X4 810 weighs in at 7.2W whereas the X3 720 draws a "whopping" 10.6W. Note that the Core i7 numbers are isolated core power only as explained in our Nehalem power analysis article.
We measured the power about a dozen times for both the X4 810 and the X3 720 since at first glance the numbers didn't make sense. That is, the X4 810 perfectly matches the expectatiions based on the previous measurements of the X4 940 as long as we take into account the smaller L3 cache. However, the X3 720 numbers don't quite add up unless the L3 power consumption is the dominating factor at idle, which, with the full size cache and the higher frequency, along with a slightly higher VID compared to the X4 940 could explain our measurements. Either way, even some 10W are nothing to complain about.
{mospagebreak_scroll title=Full Load Power Consumption}
Full Load Power Consumption
There is not much to explain about importance of full load power consumption other than that it sets the minimum requirements for the board power supply circuitry as well as for the cooling prerequisites. All Socket AM3 are rated at a 95W TDP, down from 125 or higher on the AM2+ SKUs, which, given our power measurements makes perfectly sense since none of the CPUs we measured came even close to the rated numbers, even though we measured "before" the VRM.

Power consumption in [W], lower is better. The picture shown here is more consistent with what we would expect from a missing core. Note that also here the Core i7 numbers are isolated core power only as explained in our Nehalem power analysis article.
{mospagebreak_scroll title=TrueSpace 5 and Power Efficiency}
Photorealistic 3D Rendering
Caligari TrueSpace 5.1
TrueSpace is a fully multithreaded rendering application and uses essentially all resources of any CPU. We used Adam Trachtenberg's Vases at 1024x768 pixels with 2 x AA enabled.

Render Time
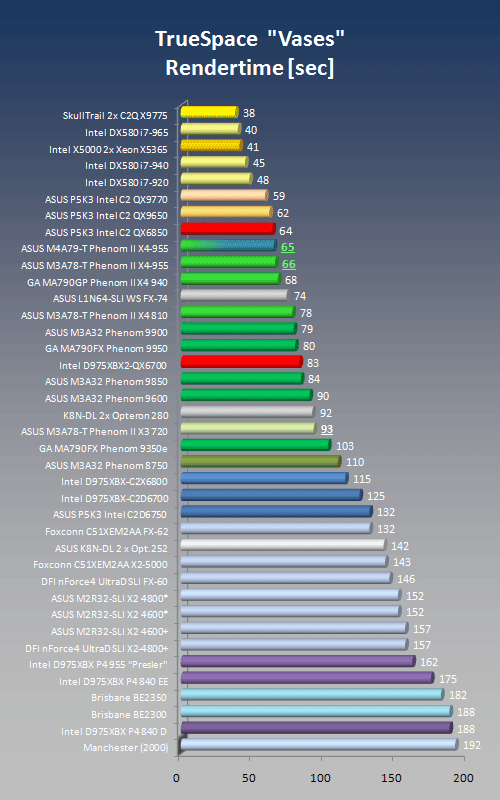
Rendertime in seconds, lower is better! The fact that the X3 720 only runs on three cores shows in the increased render time, even though the scaling is not perfect. Also, a larger L3 cache doesn't appear to make much difference.
Power Efficiency

1W * 1 sec = 1 Joule. The total time to complete the render pass times the sustained power draw equals the amount of electrical energy [Joules] used by the CPU. Lower is better. Both newcomers earn top scores. On the other hand, if the rest of the system power consumption is taken into account, the faster processing time of the quad-core CPUs will increase the gap between the X4 and the X3.
NOTE: Since we don't have accurate Core i7 numbers because of the CPU tapping into multiple sources, we have to omit the respective numbers.
{mospagebreak_scroll title=TrueSpace 7.5 with VRay 1.51}
Caligari TrueSpace 7.5 with VRay 1.51
TrueSpace 5.x has been around for years and has been replaced by several subsequent generations of Caligari rendering software. TrueSpace 7.5 does not recognize the 5.xx scene format but has several sample scenes that can be used as rendering benchmarks. Just like the earlier versions, TS 7.5 is an excellent example of true thread level parallelism to show off multithreading in its best light.

We used the Ducati Monster 900 model at the default "camera" perspective, 1280 x 1024 pixels screen resolution, midafternoon lighting, HDRI enabled and 2 x AntiAliasing. The render time was stopped manually.
Render Time
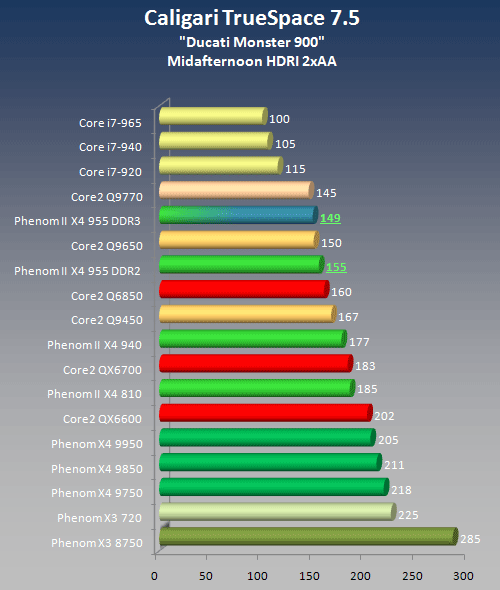
Rendertime in seconds, lower is better! As not expected otherwise, the X4 810 is very competitive, especially given the $175.- estimated street price at launch. Bottom line for the rendering community is that it is definitely worth going with the maximum number of cores available.
{mospagebreak_scroll title=Cinebench}
Cinebench Raytracing
Cinebench R9.5
Cinebench is not a commercially available software package but a benchmark which has no commercial value but does have some informative merit with respect to CPU power.

Score, higher is better!
Cinebench R10: Raytracing

If this bike was ever built, it might be a bit difficult to steer!
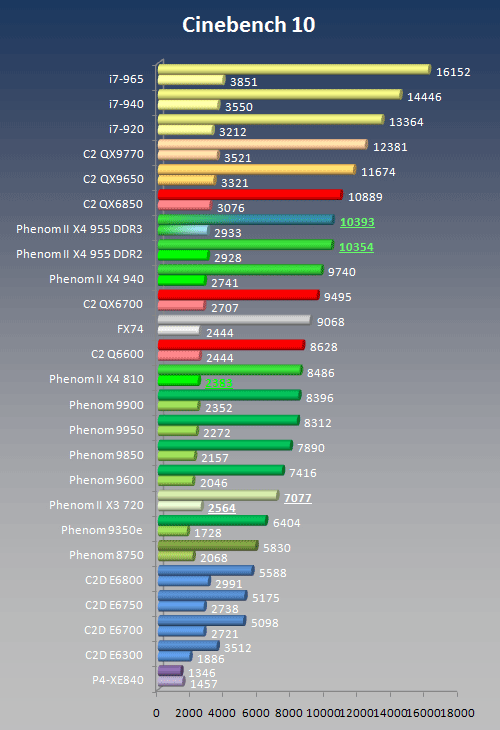
Render scores for single vs. multi-threaded render pass, higher is better!
{mospagebreak_scroll title=AV Encoding: MainConcept}
AV Digital Content Creation / Media Encoding
Overview and Methodology
Video and audio encoding are becoming increasingly important in the world of personal computing. Home-editing of videos and sound recordings are among the popular applications as is just the standard archiving of DVD material. In the case of audio encoding, there is relatively little out there in terms of multithreaded applications, meaning nobody takes advantage of multiple cores. Or if there are appications like that, they are not free and the generally short conversion times achieved with free download utilities do not provide enough incentive to actually purchase potentially faster, multithreaded applications.For this article we used three applications namely DVD-Shrink 3.2, Nero 9 (Nero Recode) and the latest version of MainConcept, namely H.264 Encoder.
In the case of DVD-Shrink we compressed John Grisham's "Runaway Jury" from 4,464 MB to 3,323MB, a compression to 59.6%. One caveat about DVD Shrink is that we found it is impossible to get relevant data points if the same physical drive is used for source and target files. In the fastest systems we have been looking at, the encoding rates were in excess of 50,000 kBytes/sec, which means that any sinble drive used as source and target would need to supply roughly 50 MB read bandwidth plus simultaneously some 50 MB write bandwidth. Aside from the issue of no current drive having that type of sustained internal transfer rate ( > 100 MB/sec), that situation would also be exacerbated by the switching between different folders for reads / writes, meaning that there would have to be platter and track switches that would further reduce the transfer rates.
We therefore used two separate drives in which the source folder and target files were placed into a dedicated partition at the OD of the drive. As a result, one drive was streaming source data to the system, the second drive was solely writing the data to the empty partition. The souce partition was defragmented before every run. By following this protocol, we largely eliminated I/O bottlenecks and as a result, DVD re-coding was improved on average by ~ 50% (e.g. 143 sec using two separate HDDs compared to 307 sec using a single physical drive). All data shown were obtained with the same protocol.
We used Intel's SSD drive as source drive and saved the resulting compressed files on the C partition of the Maxtor drive whch did not impact the outcome of the results. However, switching the configuration to make the Intel SSD the target drive resulted in a noticeable performance hit which we interpret to show the effect of relatively small file writes to the drive, which in the case of SSDs could result in low write efficiency.
In the case of Nero9 Recode, we used the same setup as for DVD-Shrink, that is,"Runaway Jury" with the Intel SSD as source drive and the Maxtor drive as target device to avoid I/O contention on either drive or interface level.
Mainconcept
In the case of MainConcept, we encoded a Watermellon.mpg file to an [H.264] High, 1920 x 1080 pixel, 29.97 fps, 48,000Hz 16 bit MPG file.
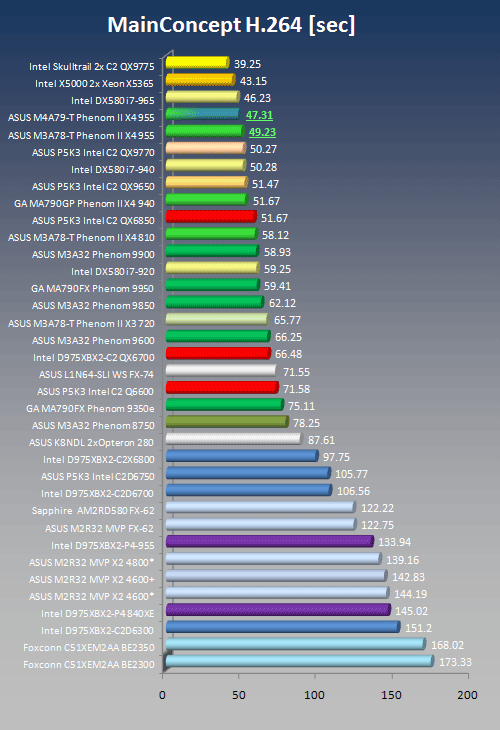
Encoding time in seconds, lower is better! If MainConcept were the only benchmark that counts, and the difference between a 51 second render time (Core i7 940) and a 58 second render time was a 3 x price tag, then AMD would be in really good shape. But the world revolves around more than just Mainconcept as we will se especially on the next page.
{mospagebreak_scroll title=DVD-Shrink / Nero9}
DVD-Shrink 3.2
DVD-Shrink 3.2 is among the most popular applications for copying DVDs to a smaller footprint, that is DVD9 to DVD5 to fit on a standard DVD. Because of DRM issues, DVD-Shrink does not run under Vista, therefore the resuls were obtained under WindowsXP only.

DVD-Shrink does not recognize processors running an odd number of cores, in which case only a single core is processing the workload consequently, the triple core scores are worse than any comparable dual core run.
Nero 9: Nero Recode
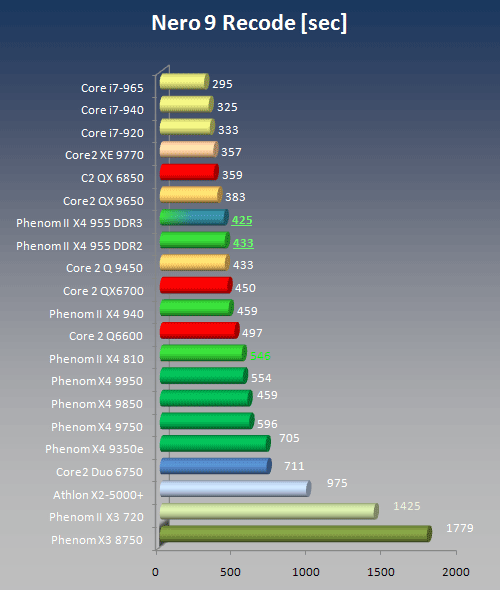
Nero appears to have issues with AMD processors in general. In Nero 7 and 8 we encountered the "divide-by-two" problem and neither did we see good results on any other of the AMD processors tested. We like Nero, though, and one of their versions is bundled with almost any of the DVD players available in the aftermarket, at least the more reputable ones like Sony or HP. After talking to them at the height of the 8.3 release, we were assured that the bugs were non-existent and would be fixed anyway in the upcoming releases. With our hopes raised high, we embarked on multiple sessions of Nero9 to find out that exactly nothing has happened, Nero still doesn't really work with AMD CPUs and not even the divide by two bug has been addressed. Unfortunately, examples of bad software like this are forming false opinions about good hardware when the culprit is somewhere else altogether. Bottomline here is that we encourage Nero to get their act together and clean up their software. Quite a few optical drive manufacturers have already started bundling competing packages.
{mospagebreak_scroll title=VirtualDub DivX 6.8}
Virtualdub / DivX 6.8
Virtualdub 1.7.1 and higher with DivX 6.8 can be run with "Experimental SSE4 Mode" enabled or turned off. Processors lacking SSE4 instructions can emulate SSE4 mode using SSE2, however, it is a no-brainer that the emulation mode will run significantly slower than the hardware instruction set-based native SSE4 mode. Running in SSE4 mode provides higher encoding quality at the same compression ratio, that is, the file size is slightly different in either case but the difference is insignificant to speak of. What it comes down to is that we have two different modes of re-coding, one that uses lower quality settings in standard mode and one that uses higher quality settings and relies on SSE4 - which only runs on Penryn core-based CPUs as Yorkfield, and Core i7, whereas older Intel processors like Kentsfield - along with the rest of the world have to use emulation using SSE2 instructions.
Update: (2/17/09)
AMD Processors Are Locked Out Despite SSE4 Instruction Set: SSE4.1 vs. SSE4a
With the Deneb/Heka core, AMD has added the SSE4 instruction set and as such we would have expected to see the SSE4 mode enabled in VirtualDub, instead of forcing the processors into SSE2 emulation. However, even the latest version of DivX does NOT enable SSE4 in the CODEC configuration panel unless it is an Intel CPU that is running. In order to understand this, it we need to take a look at the SSE4 instruction set:
SSE4 consists of a total of 54 instructions, 47 of which were introduced with the Penryn design as SSE 4.1. The Nehalem design added another 7 instructions referred to as SSE4.2 to the full spectrum of SSE4. AMD currently only supports 4 instructions of the entire SSE4 instruction set, at the same time, AMD added two additional instructions including unaligned SSE load-operation instructions (which formerly required 16-byte alignment). AMD's subset of SSE4 instructions is referred to as SSE4a and currently, aside from the four "core" instructions, the different AMD and Intel subsets are mutually exclusive. In other words, SSE4 is not necessarily SSE4.
On a side note, we have never been able to actually see the quality difference between standard encoding and SSE4 full search. Please keep in mind that the difference may be academic - or platonic when looking at the two different sets of benchmark results. The bottom line for this benchmark is that, while we are showing it, we need to make absolutely sure that everybody looking at the results is aware of the fact that DivX does not support SSE4a at this moment. However, as we also just learned, based on this article DivX is looking into implementing SSE4a into their latest CODECs
Workload Description
A 66 MB mpg file was converted to AVI format using the DivX 6.8 CODEC. The CODEC settings were specified as Experimental SSE4 full search "Enabled Using SSE2" or "Enabled using SSE4" (Yorkfield and Nehalem only). Enhanced Multithreading was enabled for each mode.
All Intel Core2 CPU-related data shown were acquired using the ASUS P5K3 with DDR3 running at the highest memory frequency supported for any given CPU - depending on the host bus frequency specification of the processor. Since the memory runs in syncronous mode at its fastest setting, the 1333 MHz processors (333 MHz bus clock) were capable of taking advantage of the same memory frequency, whereas the 1067 MHz CPUs (266 MHz bus clock) were running DDR3 at 1067 MHz data rate and the P4 840 Extreme Edition accessed the memory at 800 MHz. All Phenom-related data were obtained with the ASUS M3A32 MVP-Deluxe, the Phenom II was run on the ASUS M3A78-T.
MPG to AVI conversion - SSE4 Disabled
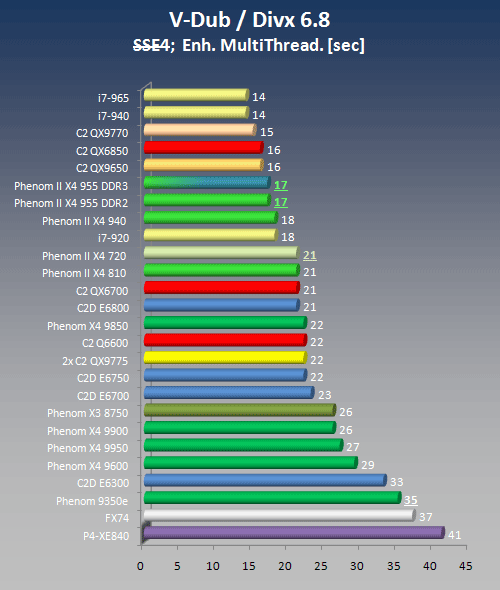
Both newcomers achieve the same score.
MPG to AVI conversion - SSE4 Enabled
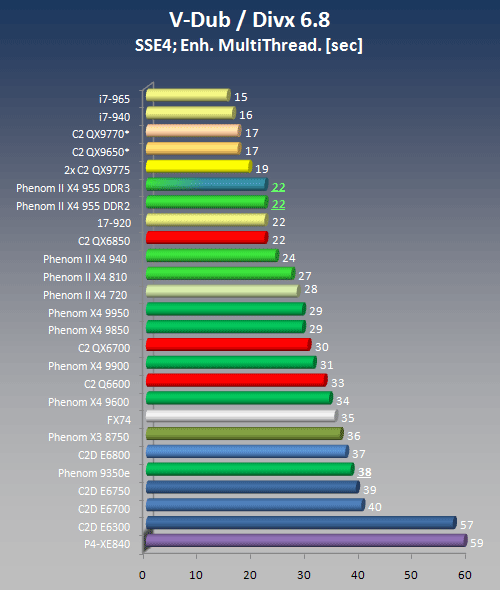
As outlined above, the scores shown here are essentially comparing apples and oranges - which will hopefully change with one of the next releases of DivX CODECs
{mospagebreak_scroll title=DIEP Chess}
Simulations
DIEP chess is simulating a chess game in which every possible move by the two opponents is simulated. The software uses exclusively integer operations to analyze the different permutations and combinations of moves. DIEP Chess is not optimized for one or the other cache strategy or size, however, it seems to get a major boost out of HyperThreading as shown below using the example of Intel's Core i7 965 (HT vs HT-).
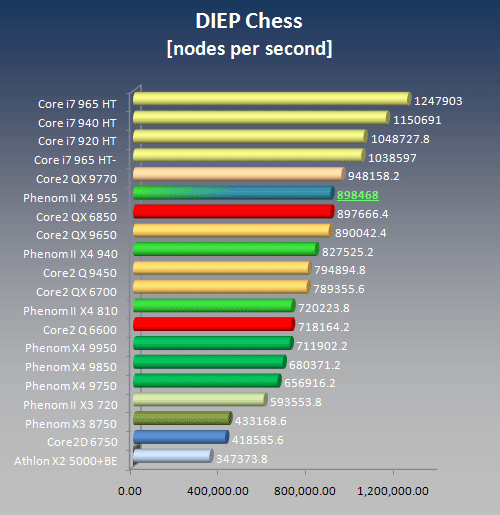
Diep chess is exclusively integer based, incorporating a plethora of chess knowledge based on real chess play in an attempt to better understand and simulate the human mind. As a result branches and branch predictions play a major role for its execution speed. As this makes the codesize quite big, also the L1i misses play a minor role together with the latency of the memory controller.
Since there is no optimization for any L3 cache size, nor are floating point operations involved that could take advantage of the FP_MOV optimization, it is not suprising that the Phenom II 940 scales in an almost linear fashion with its clock speed increase. Path-based indirect branch prediction does not appear to apply to this particular software either.
{mospagebreak_scroll title=3DMark'06:CPU Score}
3DMark'06 CPU Benchmark
Gaming applications lag behind most other high power applications with respect to their multithreaded nature. One of the few exceptions, albeit only as a theoretical benchmark is 3DM06. We only use the CPU benchmark to avoid any bottlenecks of graphics adapters.

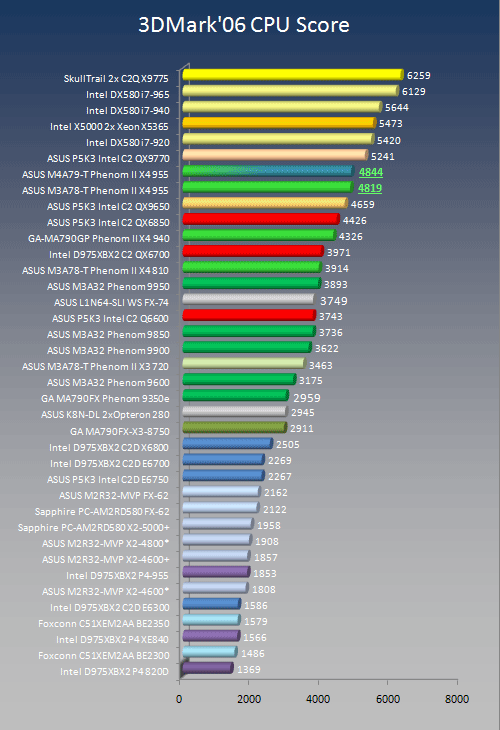
Both X3 720 and X4 810 perform better than what a linear frequency scale would predict. Needless to say that with higher frequencies, diminishing returns will start to kick in but the bottom line is that there does not appear to be any impact of the reduced size L3 cache.
{mospagebreak_scroll title=Crysis - F.E.A.R.}
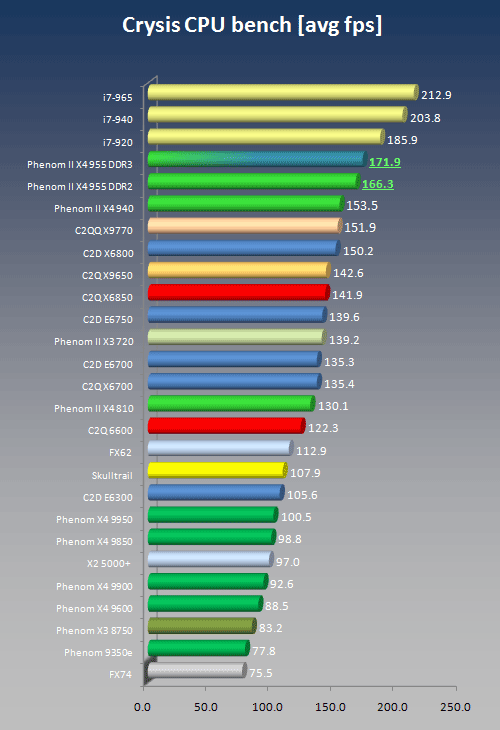
Crysis
We ran the built-in CPU benchmark at 800x600 with all graphics settings turned to "low". Crysis claims to be multithreaded but in reality we only see about 1 1/2 threads with CPU utilization maxing out around 32%. Crysis is without doubt the one gaming application that shows the highest performance increase of Deneb vs. Agena. Our original suspicion was that the performance boost might be a factor of the increased L3 cache, however, if we plot all three Phenom II processors shown here against frequency, we end up with an almost completely linear scaling. In other words, even if we cannot exlude that the larger cache helps, we can say that at least 4 MB L3 will be enough. Moreover, it is perfectly legitimate in view of the data to claim that other factors, especially fine tuning of the path-based indirect branch prediction is the key to better performance in the Deneb design.

First Encounter Assault Recon (F.E.A.R.)
F.E.A.R. is not quite the latest game but it still passes for overall CPU performance measurements. F.E.A.R. is uses essentially a single thread but it uses this thread very efficiently.

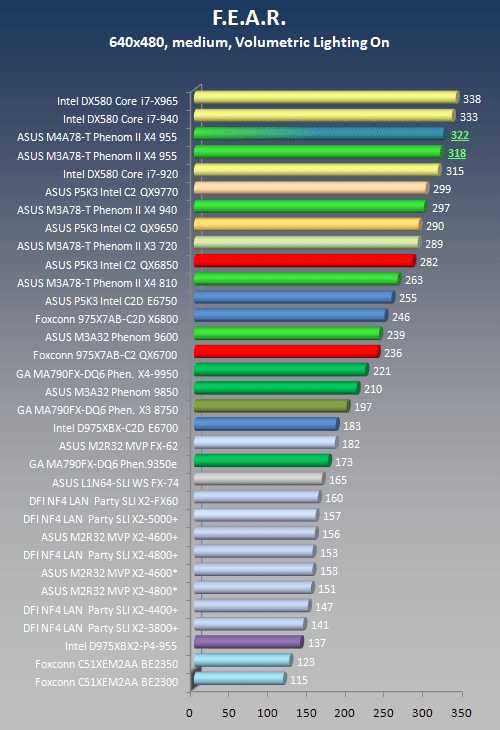
The lack of thread level parallelism is rather apparent in the scoring of Intel's Core2 Duo vs. Core2 Quad offerings. Since F.E.A.R. is a single-threaded game, it is not surprising to see the X3 720 pull ahead of the X4 810. The next question is, how much did we have to overclock the X3 720 in order to get average frame rates of 372 fps and, since we are at it, 170 fps in Crysis? The answer is somewhere on the next few pages.
{mospagebreak_scroll title=Unreal Tournament3}
UnrealTournament 3
In our initial series of benchmark, we made the mistake of not patching the game engine with patches 1-2 with the result that, despite updating the baseengine config file to specify a max smooth frame rate of 999 fps instead of the default 62 fps, we were stuck with the latter ceiling, which skewed our data in some strange ways towards AMD processors. To make up for this misfit, we recorded a custom demo in the Rising Sun level, playing 32 bots (and beating them by a landslide using the OCZ nia as game control device). The result is a demo featuring 32 individual players trying to frag each other, which puts a substantial load on the CPU - enough to completely eliminate any GPU-based bottleneck as long as the resolution was kept at 800x600.
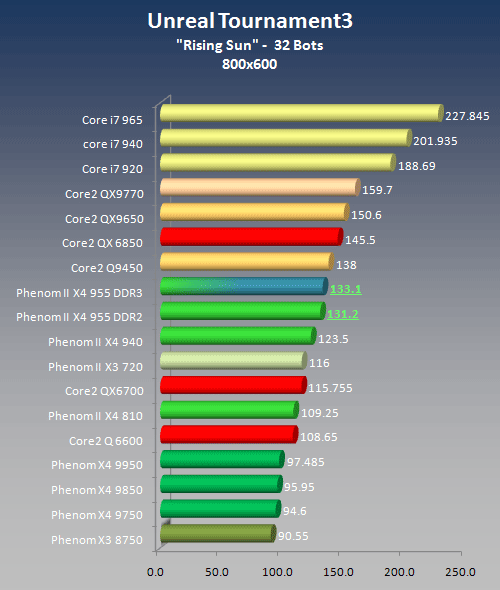
UT3 is among the better multithreaded games at this point, using all four cores to various degrees, albeit with only some 60% total CPU utilization on a quad core and roughly 80% on the X3 triple core There is a clear difference between dual and quad core CPUs based on the Conroe/Kentsfield design (which is also noticeable in game play) whereas the Phenom X3 only falls marginally behind the quad core offerings. In fact, the X3 720 is indeed faster than the X4 810 and probably the better choice.
{mospagebreak_scroll title= OC - Final Thoughts}
Overclocking
The Phenom X3 II 720 is being sold as Black Edition, meaning that the multiplier is completely unlocked, in short, an invitation for overclocking. In fact, as it turned out, I have never seen a CPU that easy to overclock out of the box without doing anything beyond moving a few sliders on AMD’s OverDrive utiliy. Set the core voltage to 1.45V, the NB to 1.325 V with a 1.235 V value for the HT interface and push the multiplier all the way to 20 x. Twenty seconds later, CPUZ showed that we were running at 4.0 GHz. 4.1 GHz caused some problems. Either setting was done with standard air cooling and at room temperature. Granted, there were a few stability problems even at 4.0 GHz but at 3.8 GHz, the X3 720 was purring along no matter what we threw at it to get 372 fps average in F.E.A.R. and 170 fps average in Crysis. Without any hiccup.

Final Thoughts
Introductory prices of US$ 125.- for the entry level Phenom II as in the X3 710 (2.6 GHz), US$ 145 for the X3 720 (2.8 GHz Black Edition) and US$ 175 for the X4 810 leave no doubt that the days of single and even dual core CPUs are counted – unless they are meant specifically for office applications or low power environments. It’s the bargain bin for Phenom II which, all things considered is a viable alternative to Intel’s offerings. Moreover, for any owners of Socket AM2 systems, the AM3 processors are a drop-in replacement for the existing CPU and as such a relatively inexpensive upgrade with the added benefit of no complicated system reconfigurations being required. If the need arises at any later point, the motherboard can be swapped out for a native AM3 solution and DDR3, where we still wait for hardware to arrive for gauging the performance differential.
Given the pricing strategies, the two main lines of bargain processors are targeted towards different user groups with the X3 700 series probably appealing most to the gaming community – after all, the graphics cards are the limit anyway. The – slightly more expensive - X4 810 is appealing mostly to the digital content creation community and, no worries, it doesn’t seem as if there is any major impact of the reduction in L3 cache size from 6 MB to 4 MB. This conundrum is actually not as surprising as it seems at first glance. After all, large on-die caches provide major benefits for architectures where the memory system is somewhat limited in bandwidth and latency, and the L3 cache can serve as a speculative prefetch buffer. Particularly in the case of Intel’s AGTL bus, we can appreciate tangible benefits if large data chunks can be stored in a shared cache to bypass the need for a majority of main memory accesses. On the other hand, looking at the latencies and bandwidth of the Phenom (II) or else the Core i7 architecture, the benefits of the large L3 can be seen primarily in a consolidation of shared data in the proximity of the cores – in which case, the question becomes “how much is enough?” In that context, we also have to remember that especially the 800 series is going to be desktop only, meaning that there are no requirements for virtualization in the majority of cases – which could tax the L3 a bit more heavily and that is where a clear performance distinction could be between the full size Shanghai/Deneb and the lower L3 cache size desktop versions.
At the end of this article we are left with the question which one of the two new CPUs is our favorite and the short answer is: The X3 720 BE! The long answer is … Well, you may have just read some 17 pages about that.